本文是对 Dart 官方 VM 的介绍的总结摘要,推荐直接阅读官方原文。
Dart VM is a collection of components for executing Dart code natively. Notably, it includes the following:
- Runtime System
- Object Model
- Garbage Collection
- Snapshots
- Core libraries’ native methods
- Development Experience components accessible via service protocol * Debugging * Profiling * Hot-reload
- Just-in-Time (JIT) and Ahead-of-Time (AOT) compilation pipelines
- Interpreter
- ARM simulators
下图是 runtime 执行代码的示意图:
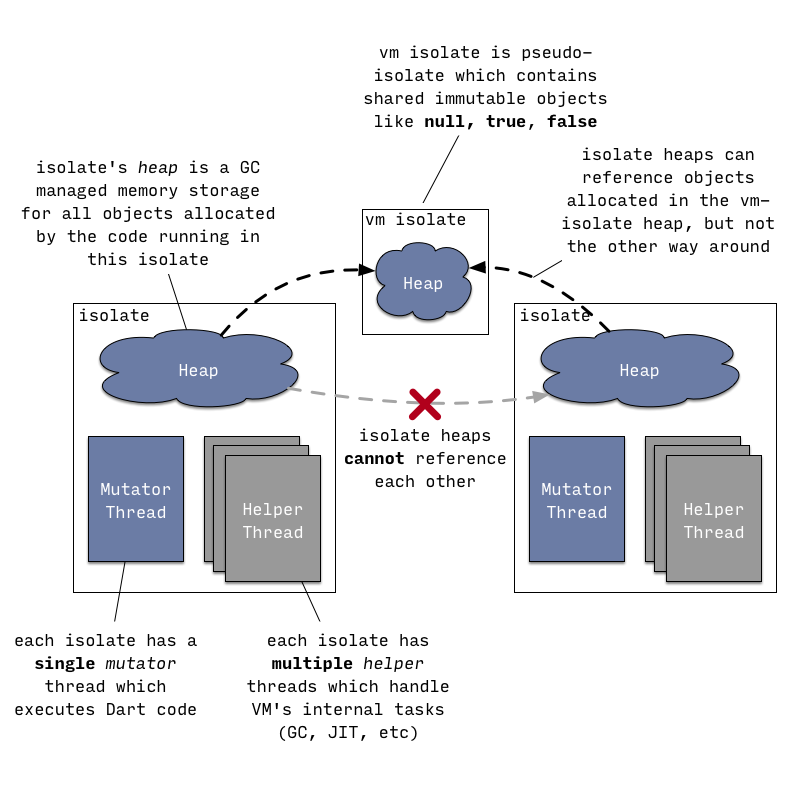
isolate 中有两种 Thread:
- 一个 mutator thread 用来执行 dart 代码
- 多个 helper thread 用来执行 GC、JIT 等
此外,一个 isolate 有一个 heap,用来存储所有的 dart object(GC 发生在这里)。
一个 OSThread 一次只能进入一个 isolate,当其进入之后,该 isolate 的 mutator thread 便和这个 OSThread 关联起来执行 dart 代码。当 OSThread 要进入一个 isolate 的时候,必须先退出当前关联的 isolate。
isolate 的 mutator thread 可能在不同时间关联不同的 OSThread,但同一时刻最多只能有一个 OSThread。
VM 执行 Dart 代码有两种方式:JIT 和 AOT,不管哪一种都不会直接执行 Dart 源码,而是经过转化之后的 Kernel Binary(also called dill files)which contain serialized Kernel ASTs。
一般来说,从 Dart source code 到 Dart VM 执行分为下面几步:
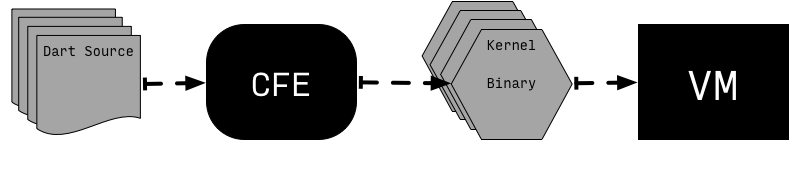
VM expects to be given Kernel binaries (also called dill files) which contain serialized Kernel ASTs. The task of translating Dart source into Kernel AST is handled by the common front-end (CFE) written in Dart and shared between different Dart tools (e.g. VM, dart2js, Dart Dev Compiler).
Dart VM has multiple ways to execute the code, for example:
- from source or Kernel binary using JIT;
- from snapshots:
- from AOT snapshot;
- from AppJIT snapshot.
1. Running from source via JIT.
从 Dart Source 加载到 VM 中
为了保证直接从源代码执行 Dart 的便利性,独立的 dart 可执行文件承载了一个称为内核服务(*kernel service)*的辅助 isolate,它处理 Dart 源代码编译成内核的过程。然后,VM 将运行产生的内核二进制文件(Kernel Binary)。
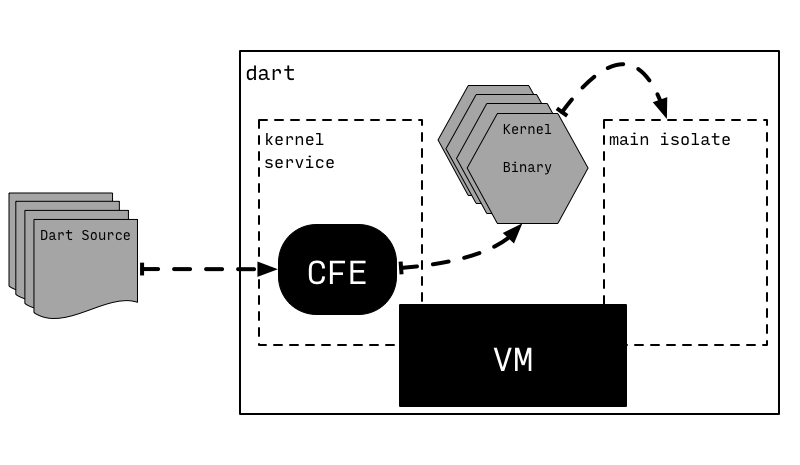
上图中,一个被称为kernel service的 isolate 使用 CFE 将 Dart Source 编译为为Kernel Binary然后交给 main isolate 执行。
这并不是安排 CFE 和 VM 执行 Dart Source 的唯一方式,比如 Flutter 就将 CFE(封装之后的)和 VM 分别置于两个设备上:
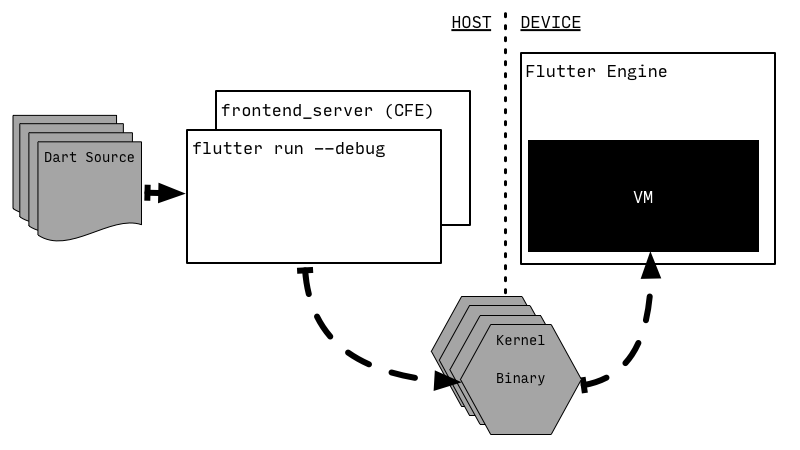
当热更新触发时,Flutter 使用封装过的 CFE 以及一个 Flutter 独有的 Kernel-to-Kernel 转换,将修改过的 Dart Source 编译为 Kernel Binary,然后推送到设备上面(比如手机)执行。
在 VM 中执行
上面是 Dart Source 加载到 VM 的过程,下面是Dart 代码在 VM 中执行的过程分析:
1)当Kernel Binary加载到 VM 中之后,只会解析加载的类和库的基本信息。
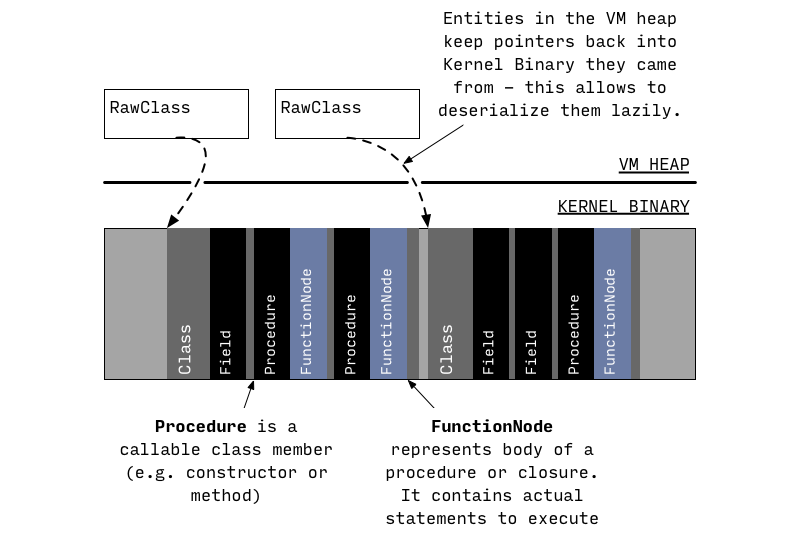
2)当 runtime 实际用到的时候才会去获取完整的信息用来创建对象分配内存等:
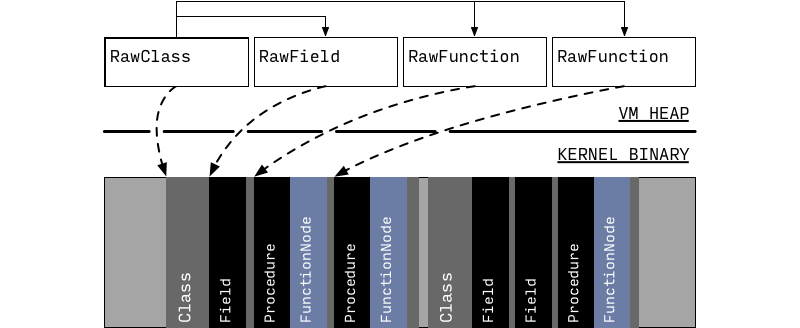
此时,从Kernel Binary中读取出了class members,此时已经有足够的信息让 runtime 用来调用方法(successfully resolve and invoke methods)了,比如调用 main 方法,但是具体的方法体此时依旧还没有被反序列(deserialized)。
3)在这个阶段,所有的 function 只是持有了一个真正要执行的方法体的placeholder指向LazyCompileStub,当 runtime 要执行的时候再创建并运行可执行代码。

这时候执行方法有两个阶段:
- unoptimized 默认执行时直接从Kernel Binary创建IL然后转化为machine code并运行
- optimized 在 a 阶段的热点代码会被从普通IL优化为SSA IL,然后转化为machine code运行,如果遇到优化失效的,再回退到 a 阶段执行代码(后面是否需要再走 b 阶段,需要重新判断)
unoptimized code
这个阶段,从Kernel Binary生成Machine Code主要分为 2 步:
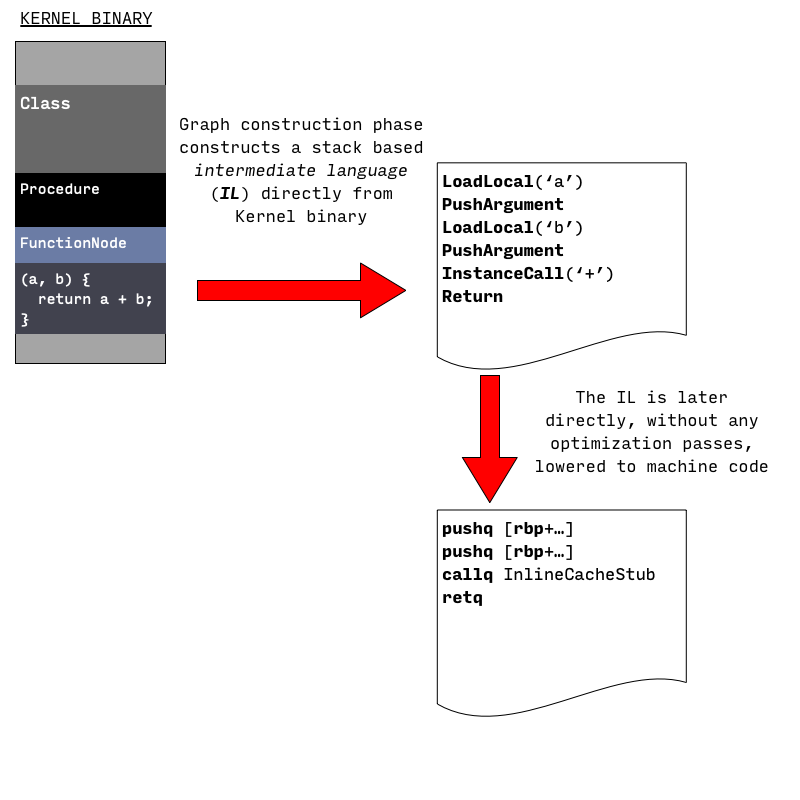
(1)Kernel Binary → IL
在这个阶段,从Kernel Binary中的AST中解析产生对应的control flow graph(CFG)。
CFG 由intermediate language(IL) 组成,这个阶段使用的 IL 指令类似基于 stack 的虚拟机:他们从 stack 中读取操作数,执行操作,然后将结果 push 回这个 stack 中。
但并不是所有的方法都有对应的Dart/Kernel AST bodies(比如一些native方法或者artificial tear-off functions generated by Dart VM),这种情况下,他们凭空创建(in these cases IL is just created from the thin air)。
(2) IL → Machine Code
由一条 IL 对应生成多行 machine language instruction
在这个阶段不会进行优化,主要目的是快速创建出可执行代码(produce executable code quickly)
内联缓存(inline caching)
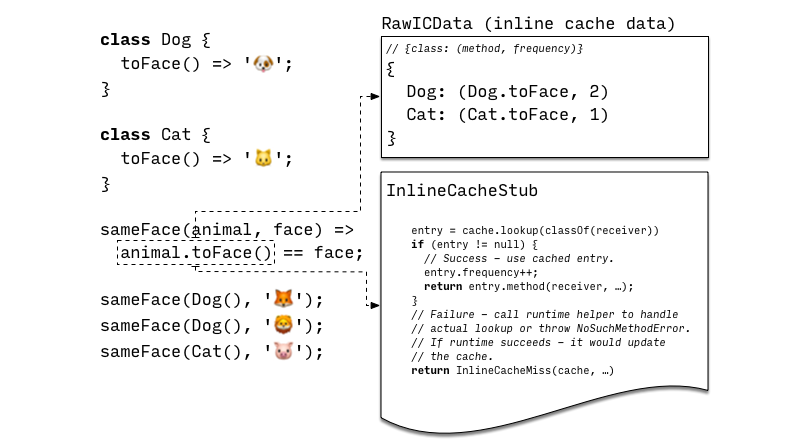
在这个阶段,编译器(unoptimizing compiler)不会尝试静态解析任何没有在 Kernel Binary 中解析的调用(any calls that were not resolved in Kernel binary),因此调用 (MethodInvocation or PropertyGet AST nodes) 被认为是完全动态的,VM 使用内联缓存(inline caching)来实现动态调用。
内联缓存的实现主要有:
- 一个call site specific cache,将调用的类与方法映射在一起,如果 receiver 和已有的缓存类对应,那么就应该调用对应的方法,还有个计数器(invocation frequency counters)标记这个方法被调用多少次(对应下文的 RawICData)
- 一个共享的lookup stub,实现了方法调用的最快路径(method invocation fast path),在发生调用时通过 lookup stub 查询是否有 entry 与 receiver 的类匹配,有的话就用调用 entry 并增加 frequency counter;否则就调用系统的 runtime system helper 兜底(如果成功运行了就更新上面的缓存,这样下次调用就不用再走 runtime 了)。
optimized code
虽然Unoptimizing compiler可以执行任意 Dart 代码,但是太慢了,所以在以上述方式执行代码的同时会记录以下信息:
- Inline cache 收集在调用点的receiver 类型(receiver types observed at callsites)
- 和方法对应的 execution counters 以及 basic blocks within functions 追踪代码的热点区域(hot regions of the code)
Optimized compilations 和 Unoptimizing compiler 开始的步骤类似:
(1) Kernel Binary → unoptimized IL
(2) unoptimized IL → SSA based IL → optimized IL
当上述代码执行的时候,如果程序调用计数器(invocation frequency counters)到达某个阈值,这个方法就会被交给一个后台优化编译器(background optimizing compiler)来优化,将 unoptimized IL 转化为*SSA(static single assignment)*形式的 IL。
最后将 SSA IL 优化为 optimized IL。
(3) optimized IL → machine code
在优化完成后,编译器会要求 mutator thread 进入 safepoint 并将优化后的代码绑定到方法上(attaches optimized code to the function)。
safepoint 的含义是,thread 关联的 state(比如 heap,stack frame 等)是一致的,并且可以在不中断线程的情况下访问或修改。通常意味着 thread 被暂停,或者在当前环境外(比如执行 native 代码)。
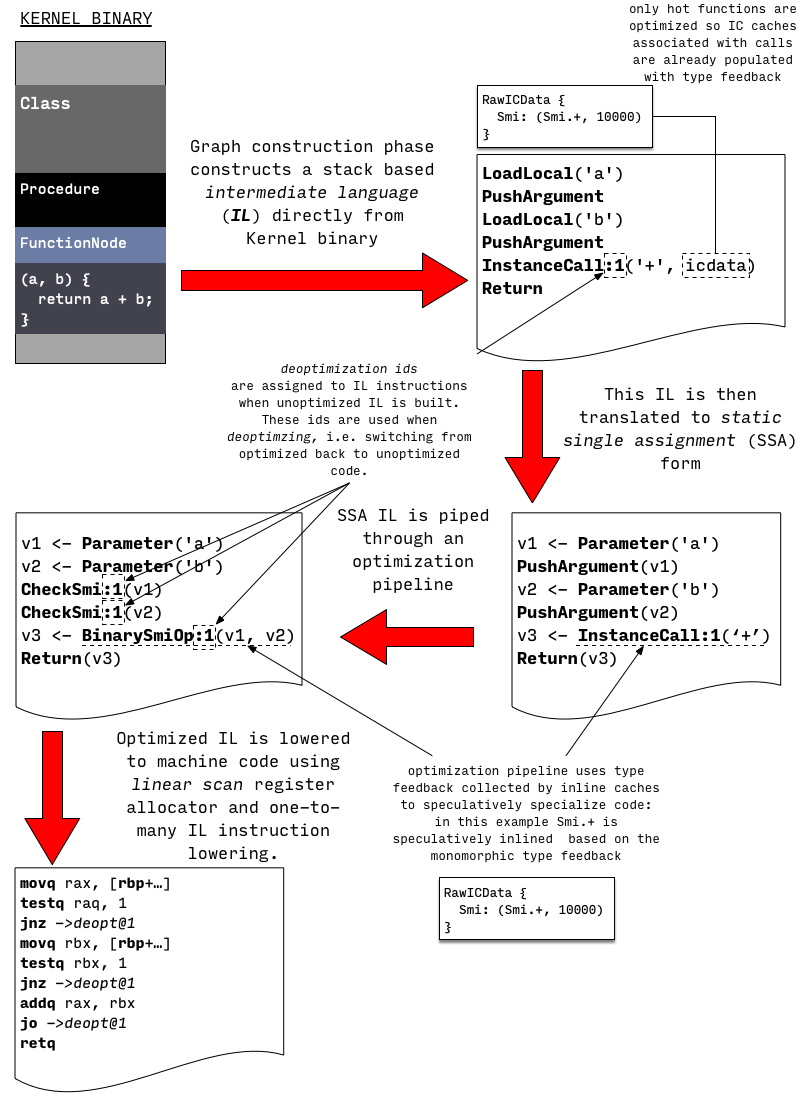
上述这种基于乐观假设的优化,可能没法处理部分情况,从而回退到未优化的代码(deoptimization),然后再执行未优化过程(通常会丢弃优化后的代码,再判断是否有热点代码需要优化),主要有 2 种方式:
- eager deoptimization 在内联检查的时候,判断优化的条件是否满足,不满足的话就丢弃优化代码
- lazy deoptimization 全局分析指示在更改优化代码的内容时丢弃优化代码(之前优化的条件不满足了)。
2. Running from AOT snapshot
Snapshot's format is low level and optimized for fast startup,包含了要创建的 object 以及如何关联这些对象的说明信息(instructions)。
VM 可以将 Heap/甚至是 Heap 中的 object graph 序列化成为 snapshot,然后再从这个 snapshot 中重建对应的状态:

最初的 snapshot 并不包含 machine code,直到 AOT compiler 的出现。
AOT compiler 和 snapshot-with-code 使得 VM 可以在那些 JIT 受限的设备上运行:
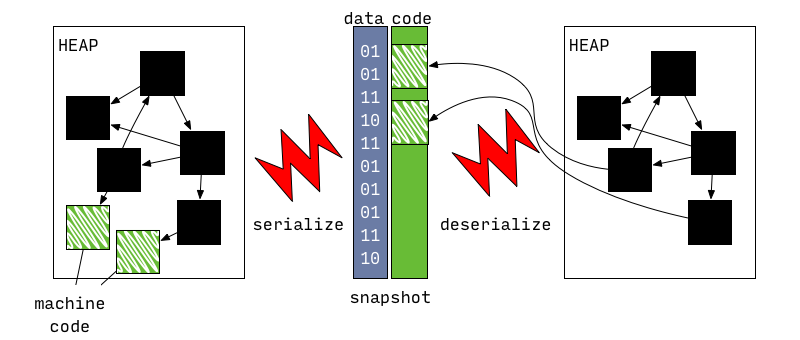
snapshot-with-code和普通的snapshot基本一致,唯一不同的是多出的 machine code 不需要 deserizlization,事实上 machine code 在被分配到内存后可以立即成为 heap 的一部分(directly become part of the heap after it was mapped into memory)。
3. Running from AppJIT snapshot
AppJIT snapshot 主要用于减少大型 Dart application 的 JIT 热身时间。
AppJIT snapshots were introduced to reduce JIT warm up time for large Dart applications like dartanalyzeror dart2js. When these tools are used on small projects they spent as much time doing actual work as VM spends JIT compiling these apps.
他的主要实现是:先用模拟数据在 VM 上运行,然后将其生成的 code 以及 VM 内部的数据结构序列化为 AppJIT snapshot 加载到 VM 中运行,只在正式的数据和模拟训练的配置无法匹配的时候执行 JIT(execution profile on the real data does not match execution profile observed during training)。
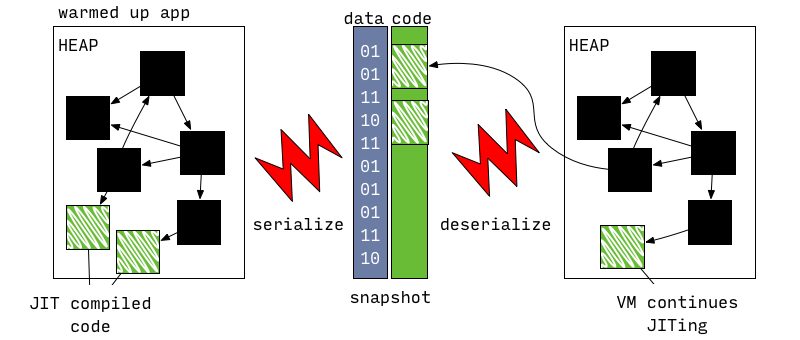
4. Running from AppAOT snapshot
AOT 与 JIT 各有优劣:
- AOT 启动时间更短
- JIT 峰值性能更优
无法进行 JIT 意味着
- AOT snapshot must contain executable code for each and every function that could be invoked during application execution;
- the executable code must not rely on any speculative assumptions that could be violated during execution;
为了满足上述要求,AOT 汇编过程会进行全局静态分析以确定程序的哪些部分是可以从已知的 entry point 触达的,分配哪些类的实例,以及类型在程序中是如何应用的(which parts of the application are reachable from known set of entry points, instances of which classes are allocated and how types flow through the program)。
AOT 上述这些分析是保守的,可能在准确性上犯错,与之相比,JIT 则在性能方面不行,因为 JIT 需要 deoptimize 兜底实现正确的行为。
所以 AOT 将所有潜在的可触达的功能编译为 native code,而无需投机性优化(All potentially reachable functions are then compiled to native code without any speculative optimizations)。
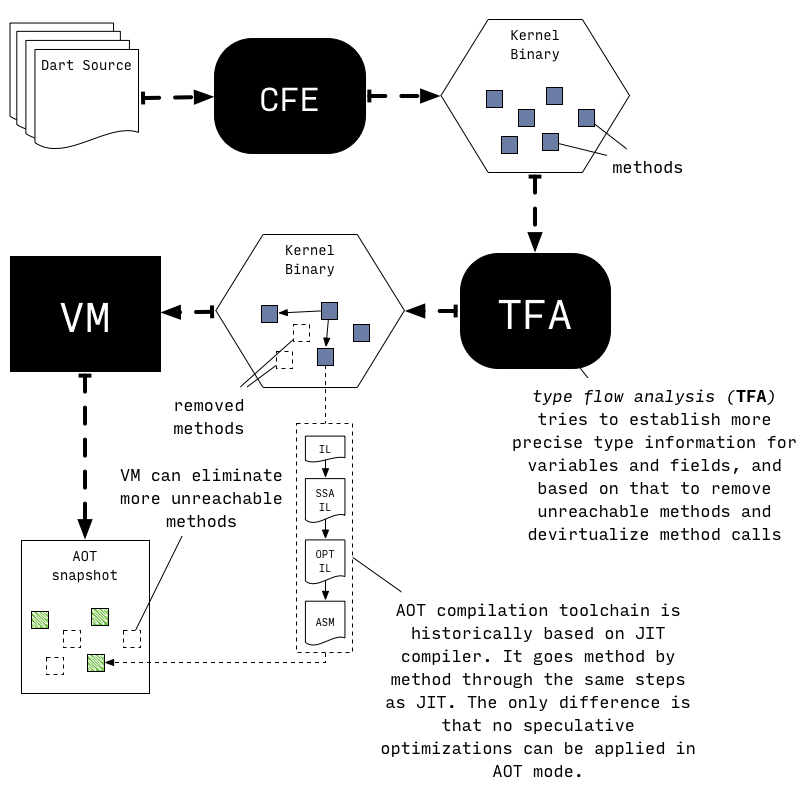
从上图可以看出,AOT 中,Kernel Binary 先经过 TFA 收集变量、方法等信息,以此来移除不可达的方法,并 devirtuablize method(确定虚拟方法的具体执行)。之后经过 VM 再移除一些不可达方法。
Resulting snapshot can then be run using precompiled runtime, a special variant of the Dart VM which excludes components like JIT and dynamic code loading facilities.
Switchable Calls
即使有全局和局部分析,AOT 编译依然可能包含一些无法被非虚拟化(devirtualized)的 call sites,为了解决这个问题,AOT 编译出的代码和 runtime 会使用 JIT 中用到的内联缓存(Inline Caching)技术的拓展——switchable calls。
有想法?欢迎通过邮件讨论。