前言
本文汇总了数据结构的优缺点及应用场景。
通用数据结构:数组、链表、树、哈希表
专用数据结构:栈、队列、优先级队列
排序:冒泡排序、选择排序、插入排序,希尔排序、快速排序、归并排序、堆排序
图:邻接矩阵、邻接表
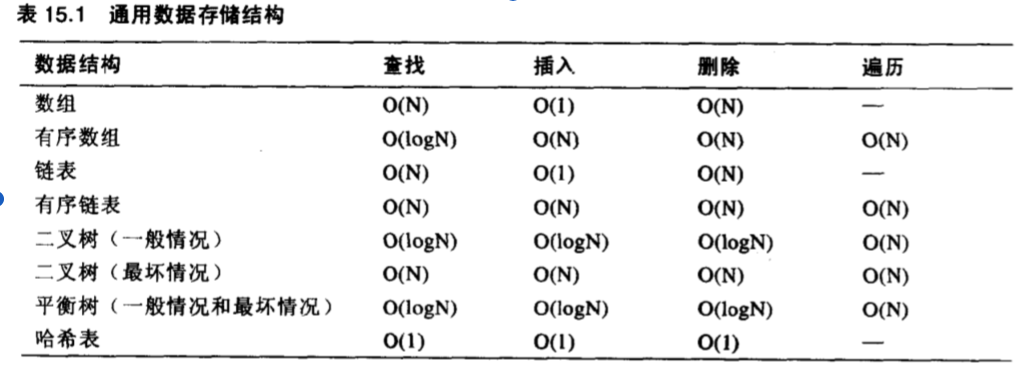
通用数据结构
这些数据结构使用关键字的值存储、查找数据
其速度如下:
哈希表 > 树 > 链表 > 数组
数组:数据量小,大小可以预测时使用
链表:数据大小不可预知,或需要频繁插入删除元素时使用
二叉搜索树:如果数组和链表都很慢时,优先考虑二叉树
平衡树:二叉搜索树很快,但是如果遇到数据是逆序的时候,就会很耗性能,而平衡树则不会
哈希表:在数据存储结构中最快,但是需要有额外的空间
下面是以上数据结构的速度:
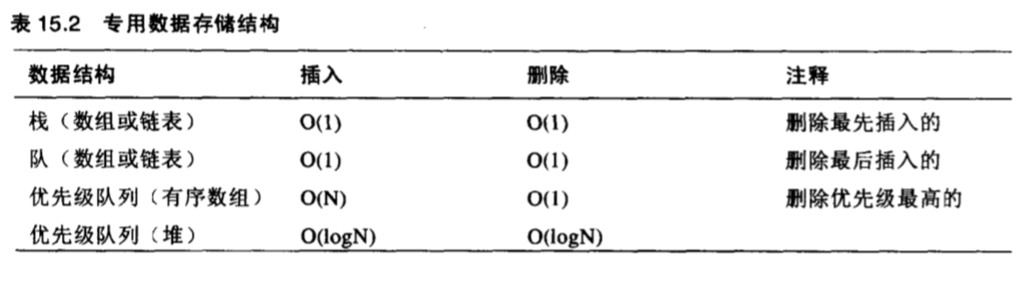
专用数据结构
包括栈、队列、优先级队列(堆),都是抽象数据结构 (ADT),由更加基础的通用数据结构组成。
不能查找或者遍历,只能访问指定元素(头部,队列也可以访问尾部)。
栈
先进后出 (FILO),最后插入的数据在栈顶,每次只能访问栈顶元素。
队列
先进先出 (FIFO),最后插入的数据在队尾,最先插入的在队首,每次先弹出队首的元素。
优先级队列
是一种特殊的队列,不同的是优先级高的在队首,优先级低的在队尾,每次弹出优先级最高的元素(这意味着每次插入或弹出时要进行排序)。
效率
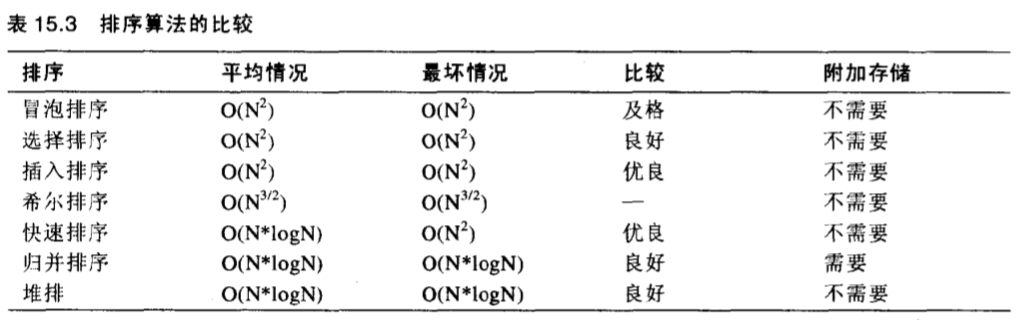
排序
排序包括冒泡排序、选择排序、插入排序,希尔排序、快速排序、归并排序、堆排序。
一般使用排序优先级:
插入排序 > 希尔排序 > 快速排序 > 归并排序 > 堆排序
归并排序:需要辅助存储空间
堆排序:需要一个堆的数据结构,比快速排序更适于非随机数据
快速排序:处理非随机数据时会慢到$O(N^2)$
下面是排序算法比较:
有想法?欢迎通过邮件讨论。