原理
注意 除非特殊说明,以下所说的计算 Java 对象大小,不涉及该对象所持有的对象本身的大小,只计算该 Java 对象本身的大小(其中引用类型对象大小只计算为 4 bytes),如果要遍历计算 Java 对象大小(包含其持有对象的大小)可以参考这篇文章 Sizeof for Java
一个 Java 对象在内存中的大小包括以下 (以 64 位 JVM 启用压缩为例,综合这里和这里的信息整理):
| 分类 | 大小(byte) | 备注 |
|---|---|---|
| 对象头 | 8 | 保存对象的 class 信息、ID、在虚拟机中的状态 |
| Oop 指针 | 4 | |
| 数据区 | 对象实际包含的数据,引用类型大小为 4 bytes | |
| 数组长度 | 4 | 只有数组对象才有 |
| 8 比特对齐 | 将对象总大小对齐到 8 字节所需的填充 |
此外,如果是(非静态)内部类的话,由于他默认持有外部类的引用,所以会比普通类的对象多 4 个 byte。
可以参照这张图
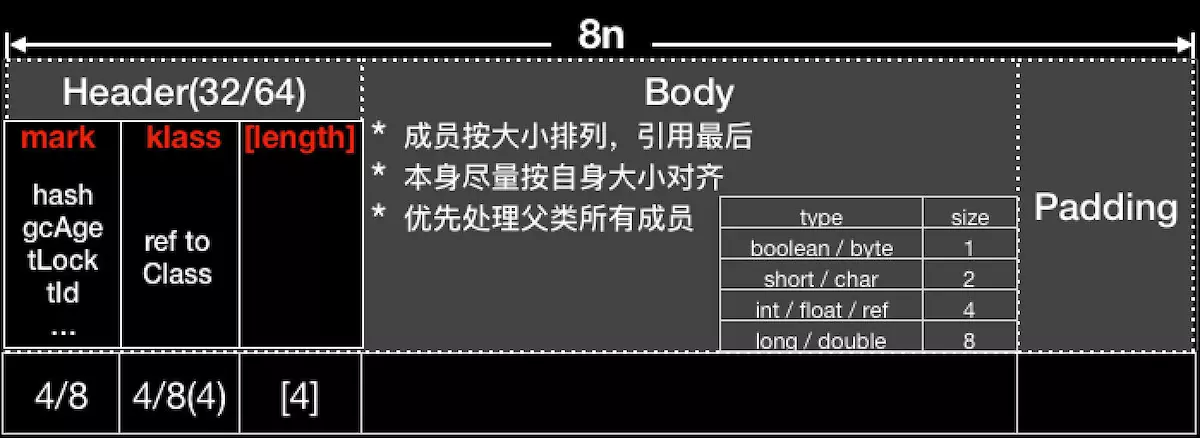
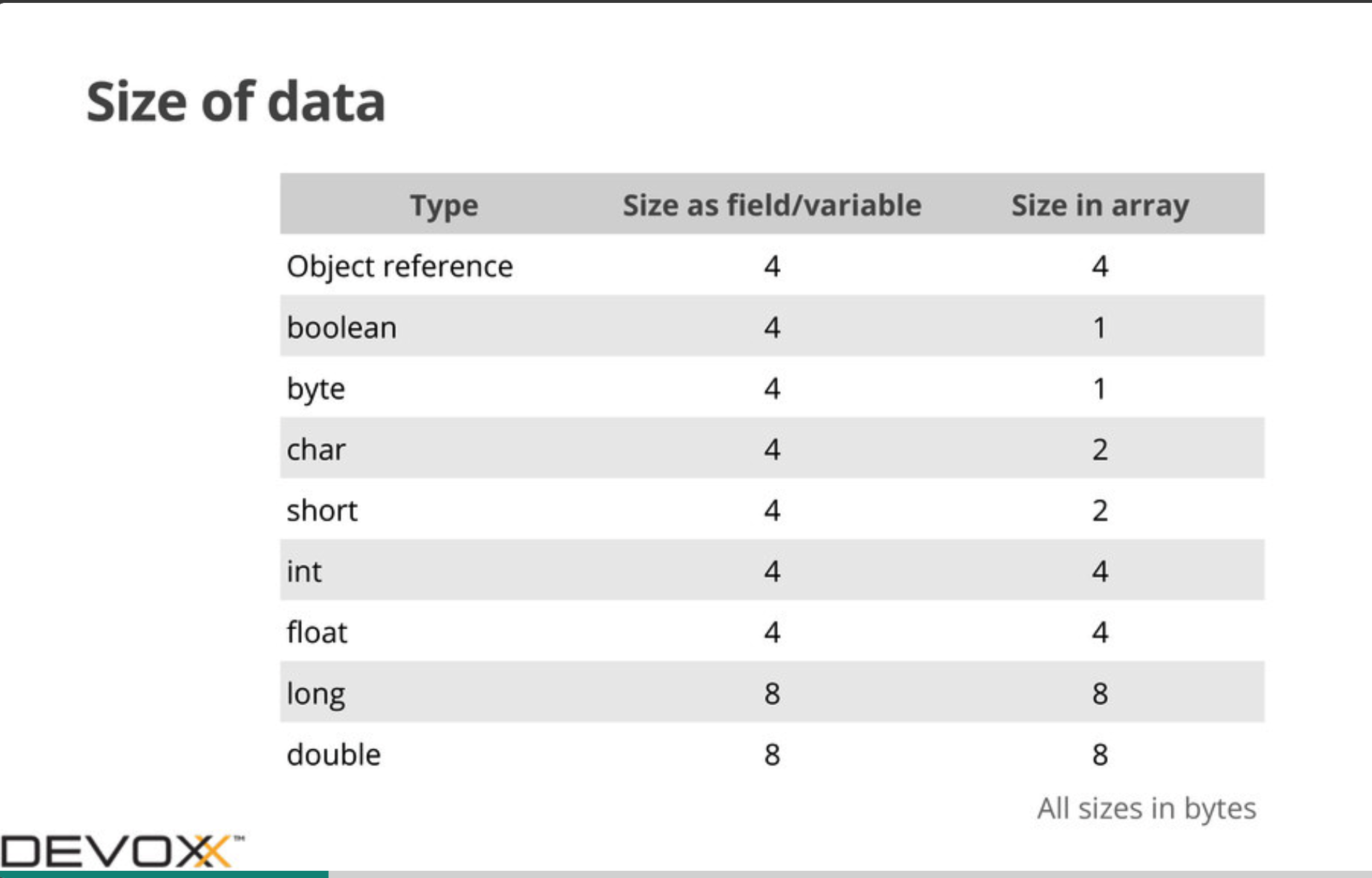
其中,数据区占用的大小如下:
(图片来自于android-memories)
##示例
根据Romain Guy在SpeakerDeck中的说法:
一个空的 class 占用了 4+8=12 个 byte 的内存,再加上 8 比特对齐,实际占用大小为 16 比特。
class Empty{
}
占用大小:
Allocation Size in bytes dlmalloc 引用 4 Object overhead(对象头) 8 Total = 4 + 8 =12 bytes
经过8-byte aligned后:total = 16 bytes
此外还有包含了数据的对象大小计算方式如下:

对于数组的大小计算(参考一个 Java 对象到底占用多大内存?和romainguy/android-memories,后者关于数组大小的计算中width&padding = 8 的意义存疑):
按照开头的公式:数组大小 = 8 对象头 + 4 Oop指针 + 4 数组大小标记length + 数组数据占用大小 + 8比特对齐
// arr0 大小 = 8 + 4 + 4 + 0 + 8 比特对齐 (0) = 16 bytes
int arr0 = new int[0];
// arr1 大小 = 8 + 4 + 4 + 4*1 + 8 比特对齐 (4) = 16 + 4 = 20 + 8 比特对齐 (4) = 24 bytes
int arr1 = new int[1];
// arr1 大小 = 8 + 4 + 4 + 4*10 + 8 比特对齐 (0) = 16 + 40 = 56 + 8 比特对齐 (0) = 56 bytes
int arra10 = new int[10];
计算对象大小的工具
具体的如何计算 Java 中 Object 大小,可以参考stackoverflow 的这个回答(这里有一份 Github 上面的实现源码)
可以参考文章:
这里提供一个实例(参考自这里):
Sizeof.java
import java.lang.instrument.Instrumentation;
final public class Sizeof {
private static Instrumentation instrumentation;
public static void premain(String args, Instrumentation inst) {
instrumentation = inst;
}
public static long sizeof(Object o) {
return instrumentation.getObjectSize(o);
}
}
Makefile
//Makefile文件
.POSIX:
.PHONY: all clean
all:
javac *.java
jar -cfm Sizeof.jar META-INF/MANIFEST.MF Sizeof.class
java -ea -javaagent:Sizeof.jar Main
clean:
rm -f *.class *.jar
在使用时先新建一个 Java 类,在其中调用sizeof()方法:
public class Main {
public static void main(String[] args) {
System.out.println(Sizeof.sizeof(new int[0]));
}
}
可以用如下命令:
javac *.java //编译当前目录下的java文件
jar -cfm Sizeof.jar META-INF/MANIFEST.MF Sizeof.class //将Sizeof.class打包为Sizeof.jar
java -ea -javaagent:Sizeof.jar Main //输出sizeOf计算结果
实际应用
String最长为 65534
String s = “”;中,在编译期最多可以有 65534 个字符
原因是,Java 中的 UTF-8 编码的 Unicode 字符串在常量池中以CONSTANT_Utf8类型表示,常量池中的所有字面量几乎都是通过CONSTANT_Utf8_info描述的。
这里面的u2 length表明了该类型存储数据的长度,而u2是无符号的 16 位整数,因此理论上允许的的最大长度是2^16=65536。而 Java class 文件是使用一种变体UTF-8格式来存放字符的,null值使用两个字节来表示,因此只剩下65536- 2 = 65534个字节。CONSTANT_Utf8_info { u1 tag; u2 length; u1 bytes[length]; }所以,在 Java 中,所有需要保存在常量池中的数据,长度最大不能超过 65535,这当然也包括字符串的定义
上面提到的这种 String 长度的限制是编译期的限制,也就是使用
String s= “”;这种字面值方式定义的时候才会有的限制。String 在运行期有没有限制呢,答案是有的,就是我们前文提到的那个
Integer.MAX_VALUE,这个值约等于 4G,在运行期,如果 String 的长度超过这个范围,就可能会抛出异常。(在 jdk 1.9 之前)
一个 String 对象,占用大小(JDK1.8)为 24 bytes(不计算持有的 char 数组占用的大小):
/** The value is used for character storage. */
private final char value[]; //一个数组对象的引用,占用 4 bytes
/** Cache the hash code for the string */
private int hash; // Default to 0 //一个 int 类型,占用 4 bytes
再加上在 64 位 JVM 中,一个对象具有 12 bytes 的对象头+引用,要求对齐到 8 的倍数 (来源2.1. Objects, References and Wrapper Classes),所以一个 String 对象的大小是:
size = ( 12 对象头 + 4 value + 4 hash ) + 4 8byte对齐 = 24 bytes
枚举类 enum
枚举类大小的计算
枚举类中的每个枚举都是该枚举类的一个对象。
enum EnumClazz{
Day,Hour,Minute,Second
}
当我们用javap查看其编译后的字节码可以看到:
//javac EnumClazz.java
//javap EnumClazz.class
final class EnumClazz extends java.lang.Enum<EnumClazz> {
public static final EnumClazz Day;
public static final EnumClazz Hour;
public static final EnumClazz Minute;
public static final EnumClazz Second;
public static EnumClazz[] values();
public static EnumClazz valueOf(java.lang.String);
static {};
}
简单计算一下这个EnumClazz的大小(不含引用对象的大小):
enumClassSize = 8 + 4 + 4*4 + 4 = 32 bytes
对象头 + 引用 + 枚举类值的引用类型 * 4个 + 4 数组引用类型
然后,我们再看一下每个枚举类的值(以EnumClazz.Day为例)的大小:
enum类的每个值实际上都继承自java.lang.Enum类:
public abstract class Enum<E extends Enum<E>>
implements Comparable<E>, Serializable {
//枚举值名称
private final String name;
//枚举值次序,从 0 开始
private final int ordinal;
}
由此,我们可以计算EnumClazz.Day的大小:
daySize = 8 + 4 + 4 + 4 + 8比特对齐(4) = 20 + 4 = 24 bytes
对象头 + Oop引用 + name + ordinal + 8比特对齐
也就是说,本例中每一个枚举类值占用 24 bytes,由此可以计算出EnumClazz实际占用的大小应该是:
realSize = enumClassSize + daySize * 4 = 128 bytes
Android 中是否应该使用枚举
关于 Android 中使用枚举和常量所占用的大小对比RomainGuy有下图的对比。

关于是否应该在 Android 中使用枚举类,可以参考下文:
https://www.liaohuqiu.net/cn/posts/android-enum-memory-usage/
https://stackoverflow.com/a/29972028/8389461
总结起来其结论就是:
当需要用到枚举类的特性时,比如非连续判断,方法重载等时就使用枚举,否则就使用占用内存更小的常量类。
SparseArray&ArrayMap VS HashMap
HashMap的数据是经过包装后保存在HashMap.Node<K,V>数组中。
下面是HashMap的结构:
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
transient Node<K,V>[] table; //4+ bytes,保存 HashMap 的键值对等信息
transient Set<Map.Entry<K,V>> entrySet; //4+ bytes
transient int size; //4 bytes
transient int modCount; //4 bytes
int threshold; //4 bytes
final float loadFactor; //4 bytes
//继承自 AbstractMap
transient Set<K> keySet; //4+ bytes
transient Collection<V> values; //4+ bytes
}
再看看 Android 提供的android.util.SparseArray类 (具体分析可参考:SparseArray 的使用及实现原理)
public class SparseArray<E> implements Cloneable {
private boolean mGarbage = false; //4 bytes
private int[] mKeys; //4+ bytes
private Object[] mValues; //4+ bytes
private int mSize; //4 bytes
}
再结合官方的描述,SparseArray类很明显要比HashMap占用更少的内存:
- 将
KEY和VALUE直接保存在数组中,避免了将其包装为一个Node对象的开销 - 由于
SparseArray类的 key 是int类型而非被自动装箱后的Integer对象,所以当同样使用int类型的key保存数据时,SparseArray类的key要占用更少的内存。
SparseArrayis intended to be more memory-efficient than aHashMap, because it avoids auto-boxing keys and its data structure doesn't rely on an extra entry object for each mapping.https://developer.android.google.cn/reference/android/util/SparseArray
但是,SparseArray有以下局限性:
在每次
put/get/remove的时候都需要使用二分法 (ContainerHelpers.binarySearch(mKeys, mSize, key)) 查找是否已经存在KEY对应的值(有的话查找其位置)在添加和删除 item 的时候都需要在数组中增删条目(耗时,尽管为了优化性能,
SparseArray在删除时只是将对于的值标记为DELETED,在下次更新该KEY对于的值时直接覆盖,或者在GC时删除)。private static final Object DELETED = new Object();HashMap 的删除涉及到数组、链表和红黑树(JDK1.8)
在容纳数百个项目时性能会比 HashMap 小大约 50%。
每当需要增长数组或获取数组大小或获取条目值时,都必须执行垃圾回收 GC。
此外,还有以下可以替换 HashMap 的 (数据来自这里):
SparseArray <Integer, Object>
SparseBooleanArray <Integer, Boolean>
SparseIntArray <Integer, Integer>
SparseLongArray <Integer, Long>
LongSparseArray <Long, Object>
LongSparseLongArray <Long, Long> //this is not a public class
//but can be copied from Android source code
此外,还有android.util.ArrayMap其特性与SparseArray类似(两者占用内存小,但是慢并且最好不要用来存储大容量的数据),只不过它支持 key 值为其他类型,占用内存大小在SparseArray和HashMap之间 (参考这里),此外ArrayMap的 API 和HashMap类似。
根据Romain Guy的计算:
保存 1000 个 int 对象的
SparseArray占用大小为:8072 bytes保存 1000 个对象的
HashMap<Integer,Integer>占用大小为:64136 bytes几乎相差 8 倍!
综上,当要保存的数据量比较小(小于几千个)的时候,如果 KEY 是基本类型,推荐使用SparseArray及其衍生类以节省内存,如果 KEY 是其他类型则使用ArrayMap;否则使用HashMap更加高效。
参考资料
除文章中罗列的链接外:
https://blog.csdn.net/u013380694/article/details/102739636
Sizeof for Java -- javaworld.com
RomainGuy-Android Memories(推荐)
有想法?欢迎通过邮件讨论。